Real-Time Generative Music System
MNS Music Engine is a real-time generative sequencing system for creating structured, adaptive music. It runs locally and renders music as it plays, without requiring cloud generation, remote inference, or pre-rendered arrangements.
The engine sits between composition, software, and performance. It uses deterministic musical logic, probabilistic variation, harmonic control, and live parameter systems to produce music that can be repeated exactly when needed, or reshaped continuously for long-form listening and interactive environments.
Our current reference implementation is built in Swift and powers MNS Studio, our internal authoring environment. The long-term value is not tied to one language or platform. The core technology is the musical decision system: the algorithms, parameter model, event layer, and runtime behavior that can be adapted across products, embedded systems, applications, games, installations, and future platform-specific implementations.
What the Engine Does
The MNS Music Engine generates musical structure as playback unfolds. It does not simply randomize notes. Each part can have its own generator, pitch range, density, rhythm, timing, duration behavior, mutation profile, harmonic relationship, and performance controls. Multiple parts then interact inside a shared transport, harmonic, and parameter system.
This makes the engine suitable for music that needs to stay responsive over time: adaptive background systems, interactive entertainment, generative albums, location-based installations, creator tools, branded experiences, and environments where static playlists or fixed stems are too limited.
- Continuous variation without losing musical identity.
- Deterministic playback from seed and preset data, allowing exact replay, testing, and authored releases.
- Deep parameter design for musical direction, intensity, density, harmony, timing, and arrangement behavior.
- Local real-time response to app state, user input, hardware control, automation, or external systems.
- Portable musical logic that can be reimplemented or integrated for the requirements of a partner platform.
Generative Sequencing Core
The heart of the system is a multi-part sequencing engine. Each part can generate melody, harmony, rhythm, arpeggiation, chord movement, or authored step material, while remaining connected to the global key, scale, progression, tempo, and arrangement state.
The current engine supports several complementary generation modes, including random-walk melody, contour-based melody, arpeggiation, chord voicing, Euclidean rhythm, and direct step sequencing. These modes can be mixed across parts to build complex musical systems from compact authored rules.
What makes the engine valuable is the behavior around those generators: probability, density, sequence length variation, evolution and restoration, note repeat, duration extension, pitch deviation, timing humanization, harmonic progression, voice leading, and mirror or avoidance relationships between parts. The result is a system that can produce music with both memory and movement.
Deterministic, Yet Alive
Generative music only becomes useful at product scale when it can be controlled, tested, recalled, and trusted. MNS Music Engine is built around seed-based determinism and isolated random streams, allowing the same musical conditions to reproduce the same result while still supporting rich internal variation.
This matters for real products. Music can be authored, tested, approved, and reproduced. The engine can then generate long-form variation from that approved musical identity instead of falling into uncontrolled randomness.
The same architecture also supports controlled change. A preset can slowly evolve, return to its original state, alter density, change sequence length, adjust harmonic direction, introduce pauses, reshape timing, or respond to product state without breaking the musical frame.
Authored Logic, Not Imitation
The engine is built from authored rules, parameters, music theory, musical constraints, and deterministic processes. It does not depend on training against existing catalogues, scraping recordings, or reproducing the surface style of other artists.
This distinction matters. Modern music technology is moving quickly, and generation alone is no longer enough. The important question is how music is generated, what material it depends on, and whether creators can understand the system behind the output.
MNS Music Engine approaches generation as composition logic rather than catalogue imitation. Musical identity is authored through presets, parameters, harmonic systems, performance rules, and sound design choices. The result can be original, repeatable, inspectable, and adjustable without a hidden dataset.
Control Architecture
The engine exposes a broad parameter surface across global musical state and individual sequencer behavior. These parameters are not just editor settings; they are designed for automation, performance, and integration.
Above the raw parameters, the system supports macros and automation. This allows many low-level musical values to be grouped into high-level gestures such as intensity, motion, stability, sparsity, or arrangement change. Those gestures make complex behavior addressable by an interface, app state, hardware controller, or authored performance.
Offline Real-Time Rendering
MNS Music Engine runs locally and renders music in real time. This is a major architectural distinction: the engine does not need to call a remote model, stream generated audio from a server, or expose private user context to a cloud music system.
The engine also produces performance events, timing data, note telemetry, automation state, and musical position information that external interfaces can observe or respond to. This matters for products that need music to synchronize with visuals, interfaces, games, wellness flows, physical installations, data streams, or interactive hardware.
The current implementation includes MIDI and transport integration, project and preset bundles, JavaScript compatibility work, and runtime systems for recording and monitoring. These are implementation details of the reference stack, but they demonstrate that the algorithm can live inside a complete local runtime.
MNS Studio
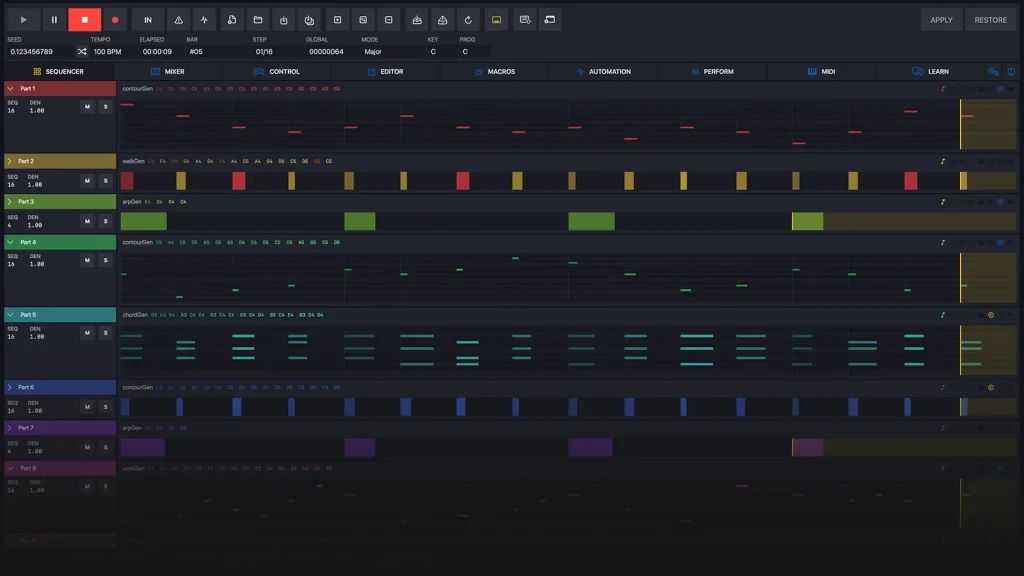
MNS Studio is our internal Swift application for authoring, testing, and performing with the Music Engine. It gives us a full front end to the engine API: project creation, sequencer editing, mixer configuration, macro design, automation authoring, MIDI mapping, performance controls, recording, and preset export.
Studio is not the only possible product form for the engine. It is our proof environment and authoring system. It lets us design musical behavior at a high level, validate runtime response, and package musical systems for future applications or partner integrations.
MNS Studio demonstrates that the engine is already inspectable and production-oriented. The same musical logic could run through a different user interface, audio stack, device target, or language runtime.
Audio and Playback Layer
The current engine stack includes built-in synthesis, sampling, effects, routing, plugin support, and recording tools. These are useful for development, authoring, demonstration, and first-party products.
They are not the core claim. The central value is the generative sequencing system. The audio layer can be retained, replaced, simplified, or rebuilt depending on the target product. The engine can drive native instruments, custom sound design, external synths, hosted audio units, game audio middleware, or an existing sound engine.
Where It Fits
MNS Music Engine is built for contexts where music needs structure, identity, and variation over time. It is not a playlist system, a stem randomizer, a prompt-to-song tool, or a dataset-driven imitation system. It is an engine for authored musical behavior.
- Consumer apps that need personalized focus, wellness, sleep, meditation, or productivity music.
- Games and interactive media that need music to react to state, pace, environment, or player behavior.
- Creative tools that need an engine for generating, controlling, and exporting musical material.
- Installations and venues that need music that can run for long periods without obvious repetition.
- Brands and platforms that need a consistent musical identity capable of infinite variation.
Depending on the product context, the engine can run through the current Swift stack, an API layer, or a target-native implementation such as C++ while preserving the core musical behavior.
Current Status
MNS Music Engine exists across implementation paths. The JavaScript engine remains relevant for browser and web-based applications, while the Swift implementation has become the most developed reference environment for MNS Studio, deeper parameter control, automation, project structure, and authoring workflows.
The important point is that the musical logic is not language bound. JavaScript can still serve web deployments, Swift currently powers our internal authoring stack, and other environments can be targeted where a product requires a different native implementation.
The next stage is bringing the engine into more real-world contexts where adaptive musical logic can create experiences that static audio cannot.